
搜索引擎蜘蛛抓取原理
搜索引擎蜘蛛的主要任务就是及时、高效地收集数量尽可能多的有用的互联网页面,并保存到原始网页数据库,供内容索引与链接分析之用。
SE蜘蛛抓取的方式就是通过超链接,一到十、十到百、百到千的方式抓取互联网上的页面,抓取原理的伪代码如下:
Crawler(S)
{
Get(S)
SS=Collect(S)
Crawler(SS)
}
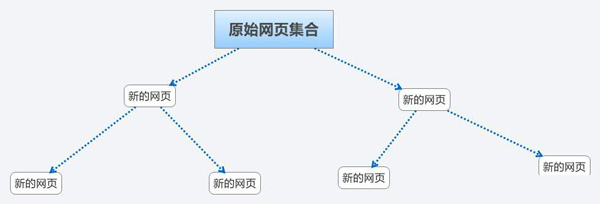
1、人工选取原始网页集合
人工选取一部分权威度比较高的拥有较多导出链接的站点,例如新浪网易等门户站点,好123等导航站点,以这一部分作为网页的原始结合;
2、蜘蛛爬行网页,并构建新的网页集合
蜘蛛爬行抓取原始网页集合中的所有网站与网页,保存到原始网页数据库,并抓取页面上的超链接,形成一个新的网页集合;
3、蜘蛛爬行新的网页集合
蜘蛛爬行新的网页集合,周而复始的循环下去,直至抓取了互联网上的可供抓取的页面。
上一篇:网页重访策略 下一篇:关键词堆积有哪些表现形式
如果您需要帮助,可以立即拨打我们的服务热线!

