
搜索引擎抓取系统构架介绍
抓取互联网的网页是搜索引擎非常重要的一步,必须尽可能的抓取所有页面并且快速,所以必须设计一个良好的抓取系统构架,保证SERP都是显示的最新的网页快照。
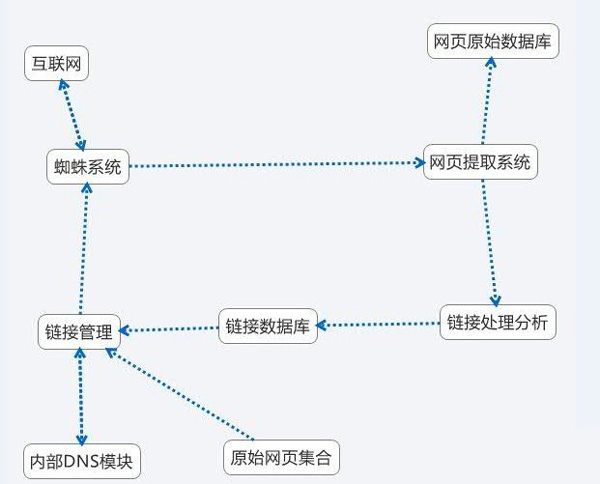
1、原始网页集合
人工选取的第一批网页的种子集合,共蜘蛛第一次抓取用;
2、链接数据库
存储链接的数据库,存储着兆级以上的链接及链接统计信息(局部PR,链接深度、URL格式、抓取日期等),供链接管理模块与链接处理分析模块用;
3、链接管理
它是爬取系统的中枢神经,负责整个抓取系统的调度任务,根据链接深度、网页类型、URL格式、局部PR等来决定网页的抓取优先级;
4、内部DNS服务
通过公共的DNS服务提供网址的解析不能满足SE抓取的高效,所以SE自己设立DNS服务器以提供高效率的解析,有事DNS服务还担任robots.txt的内容检查;
5、蜘蛛系统
爬行系统中真正去互联网交互的模块,完成爬取任务,通常采用多线程或者异步I/O抓取方式,以提高效率;
6、网页提取系统
它将提取和计算出来的网页信息存储到链接数据库中,并提取出网页中包含的链接存储中链接数据库中;
7、链接处理分析
负责链接的分析与处理,去除无意义、自动生成的、重复的链接。
抓取系统各个模块分工明确、通力合作完成抓取工作。
上一篇:标题中关键词堆积是否可取 下一篇:什么叫网站优化过度
如果您需要帮助,可以立即拨打我们的服务热线!

