
python采集新浪博客搜索列表页(搜关键词选中博主)
先按搜索列表页将所有博主的文章URL采集下来
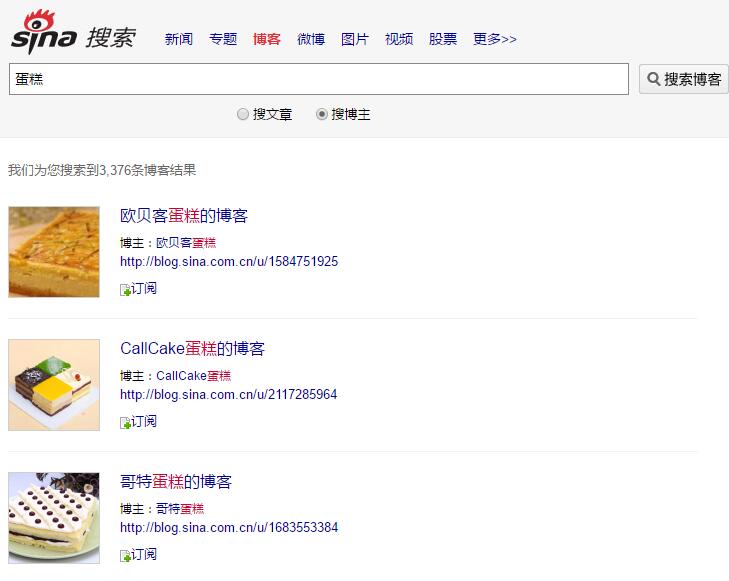 然后将所有的URL文章内容采集下来
然后将所有的URL文章内容采集下来
#coding=utf-8
import requests
from bs4 import BeautifulSoup
import os
def spider_wangye(url):
'''
网页分析准备,
打开url
获取html内容
网页结构化
'''
url=url
html=requests.get(url).content
#soup=BeautifulSoup(html,'lxml')
soup=BeautifulSoup(html, 'html.parser')
return soup
def spider_wangyenew(url):
'''
网页分析准备,
打开url
获取html内容
网页结构化
'''
url=url
html=requests.get(url).content
#soup=BeautifulSoup(html,'lxml')
soup=BeautifulSoup(html, 'html.parser', from_encoding='utf-8')
return soup
def spider_wangyeyuan(url):
'''
网页分析准备,
打开url
获取html内容
网页结构化
'''
url=url
html=requests.get(url).content
soup=BeautifulSoup(html,'lxml')
return soup
all_article_urls=[]
for p in range(1,169,1):
#for p in range(1,2,1):
pzi=str(p)
url='https://search.sina.com.cn/?c=blog&q=%B5%B0%B8%E2&range=author&by=title&col=&source=&from=&country=&size=&time=&a=&page='+pzi+'&dpc=1'
print p,url
urlyes=url
soup=spider_wangye(urlyes)
#print soup
article_urls=soup.select('#result > div > div > a > p > em')
#print article_urls
all_article_urls.append(article_urls)
all_article_urls_final=[]
for article_url in all_article_urls:
#print article_url
for url in article_url:
#print url
#url_final=url['href'].encode('utf-8')
#print url_final
url_final=url.get_text().encode('utf-8')
#print url_final
bozhuurl_final_id=url_final.replace('https://blog.sina.com.cn/u/','')
#print bozhuurl_final_id
bozhuurl_final_idzifu=str(bozhuurl_final_id)
articlelisturl_1='https://blog.sina.com.cn/s/articlelist_'+bozhuurl_final_idzifu+'_0_1.html'
#print articlelisturl_1
soup=spider_wangyeyuan(articlelisturl_1)
#print soup
articlelisturls=soup.select('#module_928 > div.SG_connBody > div.article_blk > div.SG_page > ul > li > a')
#print articlelisturls
for articlelisturl in articlelisturls:
#print articlelisturl
articlelisturlchun=articlelisturl['href'].encode('utf-8')
soup=spider_wangyeyuan(articlelisturlchun)
articleurls=soup.select('#module_928 > div.SG_connBody > div.article_blk > div.articleList > div > p.atc_main.SG_dot > span.atc_title > a')
for articleurl in articleurls:
articleurlchun=articleurl['href'].encode('utf-8')
print articleurlchun
all_article_urls_final.append(articleurlchun)
all_article_urls_final
# 创建url目录
dro = "url"
os.path.exists(dro) or os.mkdir(dro)
os.chdir(dro)
d=open('url.txt','w')
for url in all_article_urls_final:
#url_index="https://www.bokee.net"
#url=url_index+url
d.write(url)
d.write('
')
d.close()
#coding=utf-8
import requests
from bs4 import BeautifulSoup
import chardet
import os
def spider_wangye(url):
'''
网页分析准备,
打开url
获取html内容
网页结构化
'''
url=url
html=requests.get(url).content
soup=BeautifulSoup(html,'lxml')
return soup
def spider_wangyenew(url):
'''
网页分析准备,
打开url
获取html内容
网页结构化
'''
url=url
html=requests.get(url).content
#soup=BeautifulSoup(html,'lxml')
soup=BeautifulSoup(html, 'html.parser')
return soup
def article(title_gbk_txt,titleyes):
f=open(title_gbk_txt,'w')
f.write('标题:')
f.write(titleyes)
f.write('
')
f.write('内容:')
f.write('
')
contents=soup.select('#sina_keyword_ad_area2')
f.write(contents[0].encode('utf-8'))
f.write('
')
f.write('
')
f.close()
urls=open('url.txt','r').read()
all_article_urls=urls.split('
')
urltotal=len(all_article_urls)
# 创建article目录
dro = "article"
os.path.exists(dro) or os.mkdir(dro)
os.chdir(dro)
i=1
for url in all_article_urls:
if i>urltotal:
break
print i,url
soup=spider_wangye(url)
title=soup.select('h2')
print title
titleyes=title[0].get_text().encode('utf-8')
#titleyes=title[0].get_text().encode('gbk')
url_id='%d ' % (i)
#异常处理跳过
try:
title_gbk_txt=url_id+titleyes.decode('utf-8').encode('gbk').strip('?').strip(' ').strip('?').strip('@')+'.txt'
#title_gbk_txt=url_id+titleyes.decode('gbk').encode('utf-8').strip('?').strip('?')+'.txt'
except UnicodeEncodeError:
print 'oh no!'
finally:
print 'ok'
print title_gbk_txt
if '?' in title_gbk_txt:
continue
try:
article(title_gbk_txt,titleyes)
except IOError:
pass
finally:
print 'ok'
i=i+1
上一篇:【浏览器插件】搜狗打假助手 下一篇:python合并目录下多个文件
如果您需要帮助,可以立即拨打我们的服务热线!

