
Python数据抓取采集教程
做SEO的过程中,除了需要建立词库以外,也要建立内容库,然后进行数据处理,形成高质量的内容。或许今天这个Python数据抓取采集教程能够帮助到你。
做数据抓取一定一定要明确:抓取\解析数据不是目的,目的是对数据的利用
一般的数据抓取结构如下:
概要
一个简单的web数据抓取的流程就像下面的图一样
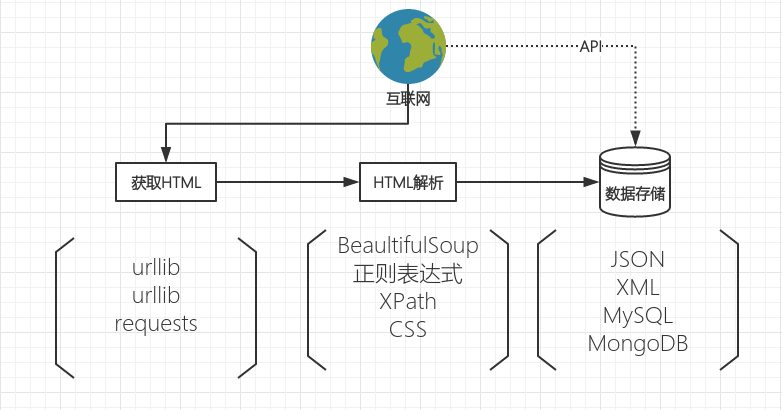
HTML获取
分析工具
- Firefox
- Firebug
工具包
- urllib
- urllib2
- Requests
- phantomjs
- selenium
反反爬虫策略
- 动态设置User-Agent
- Cookie的使用
- 时间延迟/动态延迟设置
- 使用Google/Baidu Cache
- 使用IP代理池
调度策略
HTML解析(数据清晰)
工具包
- lxml(XPath)
- CSS选择器
- BeautifulSoup
- pyquery
- 正则表达式
数据存储
工具/格式
- JSON结构化纯文本
- XML结构化纯文本
- MySQL关系型数据库
- MongoDB非关系型数据库
如果您需要帮助,可以立即拨打我们的服务热线!

